Challenges
Challenges
Below are a few common challenges the are driving the need for better observability and automation as applications are modernizing.
Challenge #1: Understanding the Legacy Application
First, we need to have a good overview of all hosts, processes, services and technologies so that we can answer the following key questions:
- Which technologies are in use and where do they run?
- Which technologies are legacy and can’t be moved because they are not supported?
- What is the big picture and end-to-end aggregate view of the legacy app services?
- Who is responsible and needs to be included in the discussion?
In our current state, we anticipate this as a few weeks of effort by our developer and operations teams to inventory the hosts, technology and dependencies. Because our IT teams are distributed and siloed by function, it may take several meetings to review the new diagrams and spreadsheets, and we will have to assign a project manager to help coordinate and keep everyone on task. All of this takes valuable time from our already busy team.
Challenge #2: Understanding application usage patterns
In addition to needing to understand the blueprint for the existing application and infrastructure landscape, we need to know how the end-user traffic patterns map to resource consumption patterns of the underlying services as to properly answer:
- What will it cost to run in the cloud?
- What network traffic will there be between the services we migrate and those that have to stay in the current data center?
- How can I make sense of all the spaghetti codes in the legacy app without reverse engineering miles of code and determining what service talks to what?
Because we use multiple monitoring and logging tools, gathering and compiling all this data can be complex and will take time. What will likely happen is that some teams will lack the resources to take on this task resulting in low confidence in the resulting analysis.
Challenge #3: Making decision for the application migration strategy
You may familiar with the 6-Rs migration strategies shown in the diagram below, but we are challenged with best determining which one makes sense for us.…
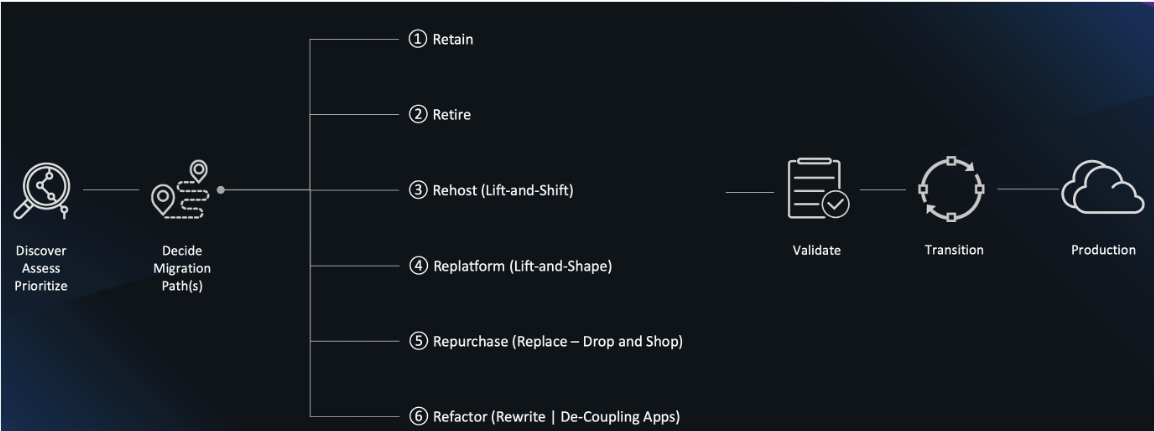
We want to balance the lower risk of just “lifting and shifting” versus benefits of the moving to new technology and the cost savings with on-demand and scalable AWS services.
What is needed to answer is:
- What are the dependencies, complexity and which pieces are most important for each component and service?
- What are the underlying infrastructure components and dependencies?
- Where are the data repositories and what is the activity?
- Which KPI’s are the most relevant?
- What is the application usage patterns (mentioned above)?
Much like the effort to gather application usage patterns, we anticipate this effort being laborious and requiring multiple teams to get involved. Again adding more time and taking resources away from other work.
Challenge #4: Benchmarking performance and ensuring service levels
As mentioned above, we have a patchwork of tools with many of them focused on a single view:
- Just host monitoring
- Just logs
- Just website traffic
There is no unified view across our current on-prem platforms let alone the cloud. As a result, we don’t know how the application and underlying services are behaving, and many of our current tools aren’t even suited to support cloud native, or new technologies like Kubernetes.
At high level, we know we must first establish system benchmarks. And then, during and post migration the following:
- Validate business outcomes
- Manage service levels real-time for full stack visibility of user experience, application and components
- Maintain single view of our hybrid cloud environment
With our current set of tooling and manual approach to aggregate all the data, we simply will not be able to keep up with the demand. This will result in blind spots and delays in gathering data and an increased risk to hurting services levels. Just this past March, we had a major outage caused by a memory leak in the legacy code and we never saw it coming.
Challenge #5: Increased Complexity for Operations
The team has quickly learned that building out cloud infrastructure, where everything is virtualized and dynamic, causes interdependencies to go way up, adding more layers of complexity.
The team understands that modernizing our legacy application to a Cloud native architecture will force a change to new way of operating in cloud. By decomposing the legacy application into small agile, autonomous applications adds complexity for operations.
We need to both scale up our team’s ability to support all this new complexity AND minimize disruption during cloud migration and prevent delays but do so without adding a whole new set of resources.
We are asking ourselves:
- Will one tool or multiple tools simplify operations ?
- How can we filter noisy incidents from the actual incident which require attention?
- How can we scale the team to support additional complexity without adding more staff?
Lets take a look at how Dynatrace can help us with these challenges.